美团多篇论文入选NeurIPS 2025:从大模型到多模态的全线突破 | 直播预告
本文精选了美团技术团队在国际顶会NeurIPS 2025中发表的10篇论文,研究方向覆盖了大模型、多模态、自然语音处理、计算机视觉、基础技术、因果推断等技术领域,希望相关研究能给同学们带来一些帮助或启发。
🎯 活动预告:「NeurIPS 2025 论文分享会 」将于 11月26日(周三)下午线上直播,我们邀请了其中4篇论文的作者分享相关知识点和技术思考,扫码即可免费报名👇

NeurIPS(Conference on Neural Information Processing Systems)是人工智能、机器学习和计算神经科学领域的顶级国际学术会议,自1987年举办以来,NeurIPS已成为全球最具影响力的学术平台之一。
NeurIPS涵盖的研究领域包括深度学习、强化学习、计算机视觉、自然语言处理等多个方向,并广泛关注跨学科的融合问题。每年,NeurIPS都会吸引来自世界各地的顶尖专家参与,展示和讨论最前沿的技术与理论。
01
PolarQuant: Leveraging Polar Transformation for Efficient Key Cache Quantization and Decoding Acceleration
论文类型:Poster
论文下载:https://arxiv.org/abs/2502.00527
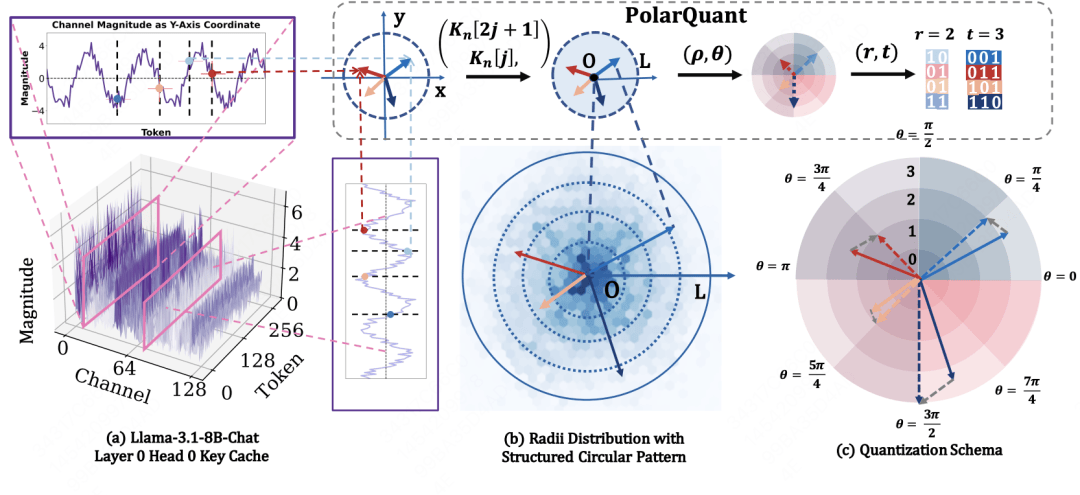
论文简介:随着长上下文生成需求的增加,大语言模型中的KV Cache成为内存消耗瓶颈。现有量化方法在Key Cache上常因异常值问题导致性能不足。PolarQuant提出一种全新视角的量化方法:通过极坐标变换发现Key向量在半径与角度空间中呈现规律分布,异常值仅出现在单维度。PolarQuant将Key向量划分为二维子向量,以量化半径和角度的方式替代直接量化原始向量,有效缓解异常值问题。进一步,PolarQuant将Query-Key内积转化为查表操作,实现KV Cache量化的高效性与解码加速,同时保持与全精度模型一致的下游性能。
02
NeedleInATable: Exploring Long-Context Capability of Large Language Models towards Long-Structured Tables
开源地址:https://github.com/wlr737/NeedleInATable
论文下载:https://arxiv.org/abs/2504.06560

论文简介:针对当前长上下文工作忽视结构化表格数据的局限,我们将经典的“大海捞针”任务拓展至表格领域,构建了一个面向表格数据的长文本评测基准 Needle-in-a-Table(NIAT),通过 单元格定位 和 单元格查找 两种问题来评估LLM和多模态LLM 面向表格中每个单元格的细粒度理解能力。我们发现,这些对人类来说非常简单的表格理解任务却对大模型和多模态大模型非常有挑战性,同时大模型在理解表格时也存在和文本领域类似的“lost-in-the-middle”的现象。此外我们还细致分析了大模型理解表格数据的注意力模式,并尝试通过合成NIAT数据的方式来改善模型在下游任务上的效果。
03
PrefixKV: Adaptive Prefix KV Cache is What Vision Instruction-Following Models Need for Efficient Generation
论文类型:Poster
论文下载:https://openreview.net/forum?id=tDG6bY48ch¬eId=tRIKfJTkvW
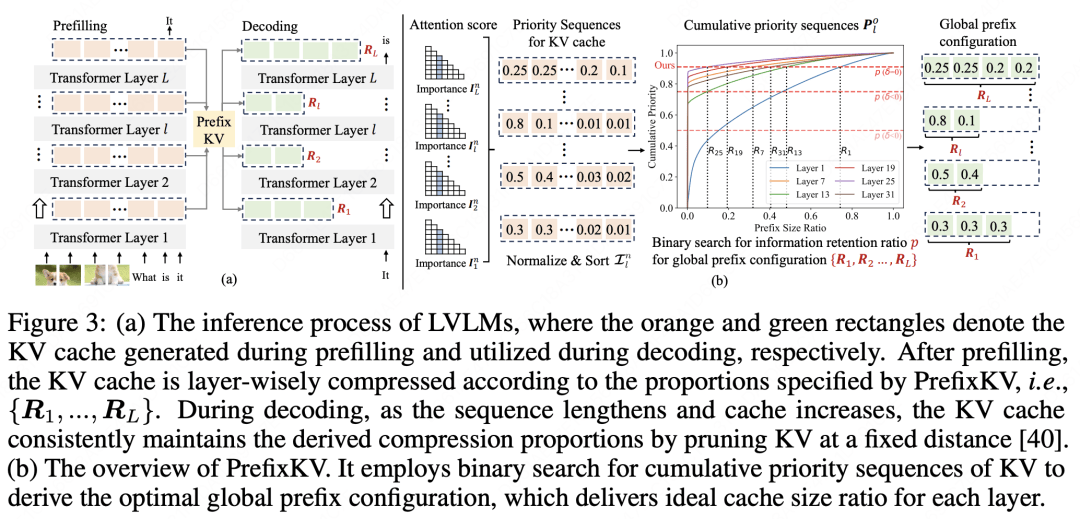
论文简介:大型视觉语言模型(LVLM)因其强大的生成和推理能力,能够处理各种多模态输入,而迅速普及。然而,这些模型在推理过程中会产生显著的计算和内存开销,极大地阻碍了其在实际场景中的高效部署。冗长的输入输出序列需要庞大的键值(KV)缓存,显著增加了推理成本。近期的研究致力于探索如何减小KV缓存以提高效率。尽管这些方法有效,但通常忽略了KV向量在不同层级间的重要性分布差异,并在每次词元预测时保持每一层相同的缓存大小。这导致某些层级的上下文信息丢失严重,进而造成性能显著下降。
为了缓解这个问题,我们提出了PrefixKV,它将确定所有层级KV缓存大小的任务转化为寻找最优全局前缀配置的任务。通过基于二分查找的自适应逐层KV保留策略,可以在每一层级中最大程度地保留上下文信息,从而提高生成效率。大量实验表明,与现有方法相比,我们的方法达到了最先进的性能。它在推理效率和生成质量之间实现了更好的平衡,展现出较大的实际应用潜力。
04
Reinforcement Learning Tuning for VideoLLMs: Reward Design and Data Efficiency
论文类型:Workshop Oral
论文下载:https://arxiv.org/abs/2506.01908
论文简介:理解复杂语义和长时序依赖的真实世界视频是计算机视觉的难题。我们提出TemporalRLT方法,作为多模态大语言模型(MLLMs)的视频推理后训练策略(GRPO)和双重奖励机制,分别监督语义与时序推理。通过难度感知的数据选择,优化学习信号。实验在八项视频理解任务(如VideoQA、时序视频定位等)中表明,TemporalRLT在显著减少训练数据的情况下,性能优于有监督微调和现有RLT方法,凸显了奖励设计与数据选择在视频推理中的重要性。
05
Glance2Gaze: Efficient Vision-Language Models from Glance Fusion to Gaze Compression
论文类型:Poster
论文下载:https://openreview.net/pdf?id=gm65gK3uOJ
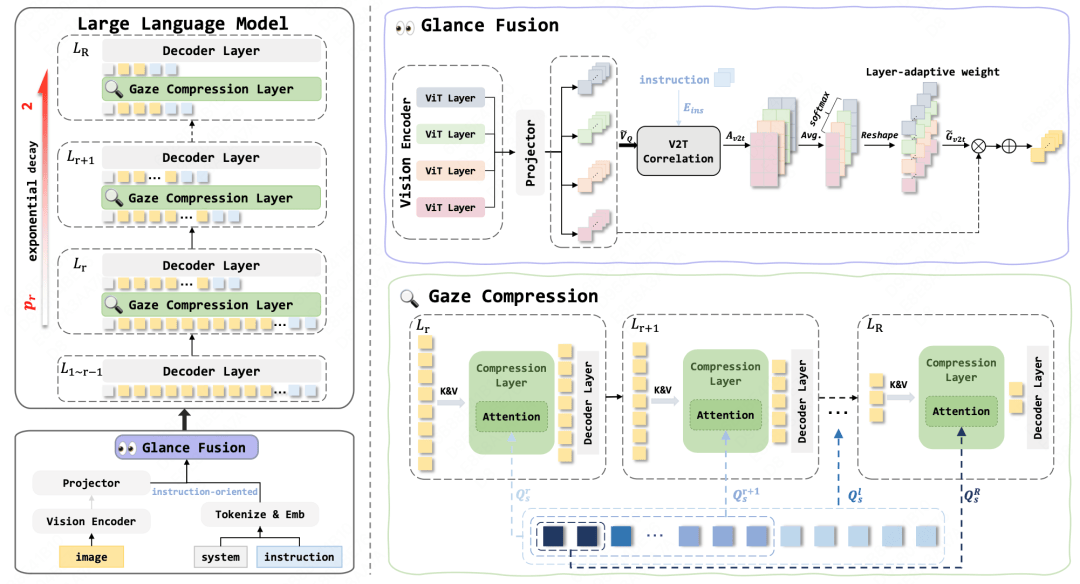
论文简介:现有视觉多模态大模型中,视觉Token的增长虽能够提升模型的理解能力,却显著增加了计算量。近期的视觉Token剪枝方法多采用丢弃视觉Token,未能模拟人类处理视觉问答的全局扫视和局部凝视的过程。我们提出语义引导的视觉特征增强策略来提升视觉表征能力,同时利用共享QueryPool的渐进式压缩策略逐步压缩视觉Token。该方法在节省70%计算量时,仅损失0.1%的性能,显著超越现有SOTA压缩方法。
06
VITRIX-CLIPIN: Enhancing Fine-Grained Visual Understanding inCLIP via Instruction-Editing Data and Long Captions
论文类型:Poster
论文下载:https://arxiv.org/abs/2508.02329
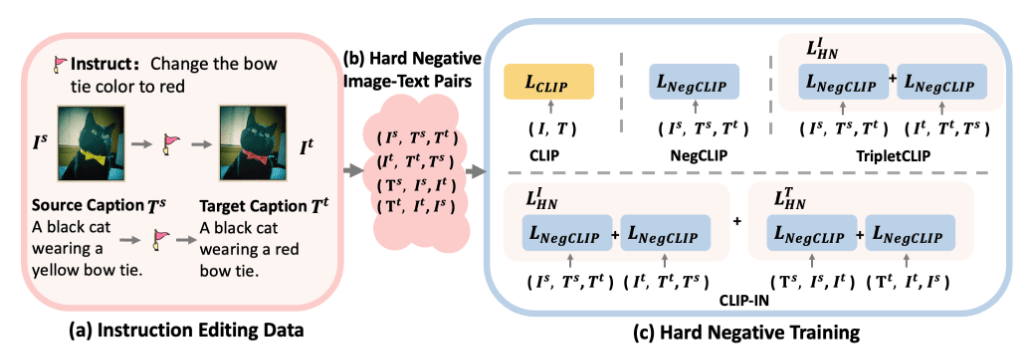
论文简介:视觉语言模型在零样本图文分类,检索任务中取得了显著进展。然而,现有方法主要聚焦于通用任务,难以提取图片细粒度特征,在面对相似度极高的图片对时会面临幻觉问题。此外,这些方法在长文本图文检索方面的能力受到了限制。为此,本文推出创新视觉语言训练框架CLIP-IN以应对图片细粒度提取和长文本图文检索方面的挑战。具体而言,在训练方面,我们使用了“指令跟随的图像编辑数据集”作为现成的“困难图文样本”并提出了“对称困难负样本损失”。同时,我们在两阶段训练框架中对带旋转位置编码(RoPE)的文本编码器进行蒸馏,使模型具有处理长文本的能力。我们的方法使基线模型在通用,细粒度和长文本图文分类与检索中都有显著提升。
07
Bi-Level Decision-Focused Causal Learning for Large-Scale Marketing Optimization: Bridging Observational and Experimental Data
论文类型:Poster
论文下载:https://arxiv.org/abs/2510.19517
论文简介:在线互联网平台需借助精细化的营销策略来优化用户留存与平台收入——这本质上是一个经典的资源分配问题。现有解决方案通常采用两阶段方案:首先利用机器学习预测各类营销活动对用户的个体干预效应,随后基于运筹学方法进行决策优化。然而,这一范式存在两个关键技术挑战:
-
第一,预测与决策的不一致——传统机器学习方法仅注重预测精度,未能充分考虑下游优化目标,导致预测指标的提升不一定能转化为更优的决策效果;
-
第二,偏差与方差的权衡——观测数据存在选择偏差、位置偏差等多重偏差,而随机对照实验(RCT)等实验数据虽具无偏性,却通常数据稀缺、获取成本高昂,最终导致估计结果方差过高。
为此,我们提出了基于决策的双层优化因果学习框架,系统性地应对上述挑战。首先,我们基于RCT数据构建决策质量的无偏估计量,通过连接离散优化梯度的代理损失函数指导模型训练。其次,我们建立了一个融合观测数据与随机实验数据的双层优化框架,并采用隐函数微分方法进行求解。这一优化框架使得无偏的决策质量估计量能够有效校正有偏观测数据的学习方向,从而实现偏差与方差的最优平衡。我们在公开基准数据集、工业营销数据以及大规模在线A/B测试中进行了全面评估,结果表明该方法相较于现有技术取得了统计显著性提升。
08
Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation
项目主页:https://meigen-ai.github.io/multi-talk/
论文下载:https://arxiv.org/abs/2505.22647
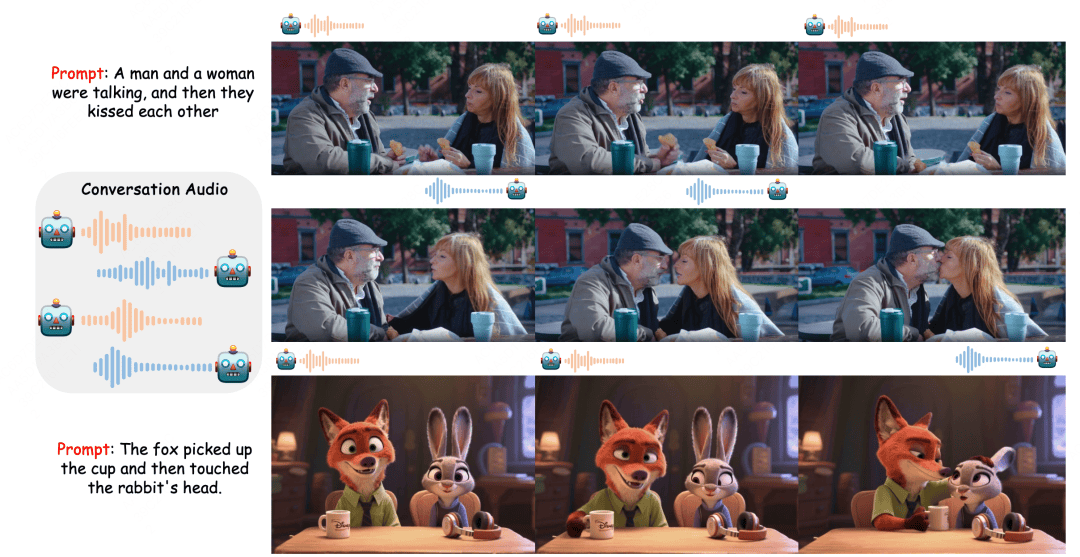
论文简介:音频驱动的人体动画方法(如说话头部与说话身体生成技术)在同步面部动作生成和视觉质量呈现方面取得了显著进展。然而,现有方法主要聚焦于单人生成,难以处理多通道音频输入,面临音频与人物绑定错误的问题。此外,这些方法在指令跟随能力方面存在局限。为此,本文提出新任务"多人对话视频生成",并推出创新框架MultiTalk以应对多人生成中的挑战。
具体而言,在音频注入方面,我们探索了多种方案并提出标签旋转位置嵌入(L-RoPE)方法以解决音人绑定问题。在训练过程中,我们发现部分参数训练与多任务训练对于保持基础模型的指令跟随能力具有关键作用。该工作已开源,受到广泛关注与好评,Github Star 2.7K。
09
DenoiseRotator: Enhance Pruning Robustness for LLMs via Importance Concentration
论文类型:Poster
论文下载:https://arxiv.org/abs/2505.23049

论文简介:近年来,大型语言模型(LLMs)在复杂推理、多模态处理和长上下文理解等方面取得了显著进展。然而,这些模型庞大的参数规模和计算需求给实际部署与推理效率带来了严峻挑战。在众多压缩技术中,剪枝因其能有效减少参数量和计算开销而备受关注。传统剪枝方法通常基于权重幅值或输出敏感度等重要性指标对参数排序,并移除评分较低的参数。
然而,现有方法往往会对模型的性能造成不可忽视的损害,其根本原因可能在于密集训练与稀疏推理之间的隐藏矛盾。在密集训练阶段,模型被隐式地激励去充分利用每一个参数,所有参数协同工作以支撑模型的表达能力;而在稀疏推理阶段,模型却被要求仅基于被保留的部分参数完成推理任务。这种训练目标与推理机制之间的内在不一致,意味着直接裁剪必然会导致部分知识或推理能力的丢失,从而引发性能下降。
针对这一根本性矛盾,我们提出了“重要性聚集”机制:不再局限于被动筛选权重,而是通过主动重塑重要性分布来提升剪枝鲁棒性。具体而言,我们开发了DenoiseRotator框架——该框架利用Transformer架构的计算不变性,通过可学习的正交变换动态调整权重重要性分布。如图所示,这些正交变换经过训练可将参数重要性集中到较小的子集中,从而在剪枝前使模型“更容易被剪枝”。DenoiseRotator在多个模型和任务上实现了显著的剪枝性能提升,为模型压缩领域提供了兼具理论深度与实践价值的新范式。
10
TARFVAE: Efficient One-Step Generative Time Series Forecasting via TARFLOW based VAE
开源地址:https://github.com/Gavine77/TARFVAE
论文下载:https://openreview.net/forum?id=3hnqwOq7iT
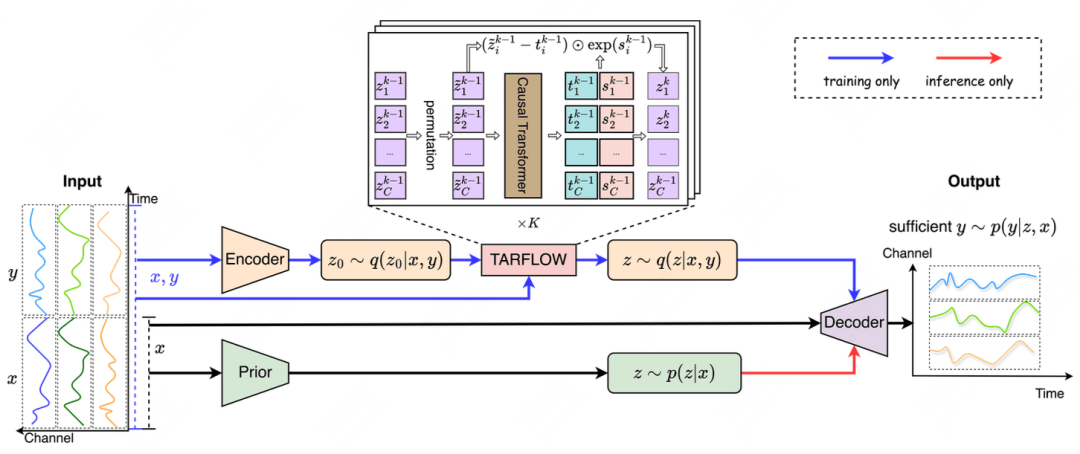
论文简介:时间序列数据广泛存在于金融、医疗等众多领域,其预测方法研究备受关注。随着生成模型在图像合成等领域的突破性进展,基于生成模型的概率预测方法逐渐成为研究热点,但现有方法普遍存在两个关键局限性:一方面依赖递归生成机制或多步去噪过程,导致预测效率低下,尤其制约了长周期预测场景的应用;另一方面现有研究多聚焦短期预测,与确定性方法在长期预测中的对比不足,实际优势尚未明确。
针对上述问题,本文提出融合Transformer自回归流(TARFLOW)与变分自编码器(VAE)的新型生成框架TARFVAE。基于"复杂时序表征网络可能非必要"的反思,我们创新性地在VAE框架中引入TARFLOW模块,通过打破传统高斯假设约束,促使潜在变量自主学习预测相关特征,构建信息更丰富的隐空间。该框架仅采用TARFLOW前向过程,规避了自回归逆运算,结合VAE解码器实现单步全周期预测生成。实验表明,仅使用多层感知机构建的TARFVAE在多个基准数据集上展现出显著优势:相比当前最优的确定性方法和生成模型,其在不同预测周期(包含长周期预测)中取得更优的预测精度,同时保持高效推理速度(单次前向计算完成预测)。这为时间序列预测任务提供了兼具高效性和准确性的新型生成式解决方案,验证了简化模型架构在保持性能优势方面的可行性。

EI Compendex,Scopus,IEEE Xplore
2026年先进电子材料与器件应用国际学术会议(AEMDA 2026)985主办
IEEE出版


IEEE Xplore,EI Compendex,Scopus
IEEE出版|2026年计算机感知与神经网络国际学术会议(CPNN 2026)IEEE出版
官方推荐


EI Compendex,Scopus
2026年光电、材料、医工高新技术国际学术会议暨第三届人工智能、光电子学与光学技术国际研讨会(AIOT 2026)IOP出版
官方推荐


